Many people around the world are getting familiar with AI tooling like ChatGPT to enhance their work or personal lives. In some ways this revolutionised our way of working. This prompted me to build some experiments of my own.
How easy is it to run this type of Artificial Intelligence yourself? Can you have your own privacy-friendly ChatGPT working, fully locally without internet connectivity? How much is actually possible without beefy hardware?
I quickly found out that the actual task of running AI locally and offline isn’t that hard. The main challenge lies in crafting prompts, capturing interesting input and envisioning how to create value out of this input.
Local AI, model choice and performance
When researching how to run a large language model locally, I quickly found Ollama. Ollama is an open source tool that allows just this. It easily facilitates the downloading and executing of AI models on your local machine.
There are several smaller, ~7b parameter models available in the Ollama library such as starling-lm, gemma, mistral, zephyr and llama2. These are ideal candidates to run without needing a massive amount of memory or special hardware.
The above models were listed in the order they are currently on the leaderboard of the LMSYS Chatbot Arena. This is a rather interesting benchmark where models are stacked up against each other based on real user feedback. While starling-lm rates highest on the leaderboard out of the smaller Ollama variants, I did find it hard to keep the answers succinct. Even when asking to not explain why a certain answer is given, starling-lm has a habit of first doing the action you requested very well. And then explaining line by line what was done and why. It really can be worthwhile to try out your prompt against several models to decide which one results in the best outcome.
Performance wise I was in general quite satisfied with running these smaller large language models on my laptop. On my Intel-based MacBook (with 32 GB RAM) I get streaming output after a short but reasonable amount of processing. On my M1 MacBook (with 16GB RAM) responses fly in almost immediately. Quality notwithstanding, Ollama on my M1 felt often faster than generally available tools like ChatGPT.
User experience with AI
Now that we have the ability to run these large language models locally, it’s time to think about how to actually use them. If you think about what functionality a text generation model can do for you, there are a couple of things to consider. What input should be used? Where does the input come from? Which prompt(s) to use? How should the generation be initiated? How fast will you get output? What should be done with the results?
In an ideal world, the AI would know what I think and execute the correct actions proactively. We are not quite there, but since we now are able to run our AI locally, we can consider how this impacts our options. I don’t want yet another chatbot. Who wants to type out all their questions anyway? On macOS nearly every application has a proper accessibility context, this is used for example by screen readers to read out what is currently visible on the screen. Using this as input context makes sense, it enables you to seamlessly action upon whatever is visible on the screen at the moment.
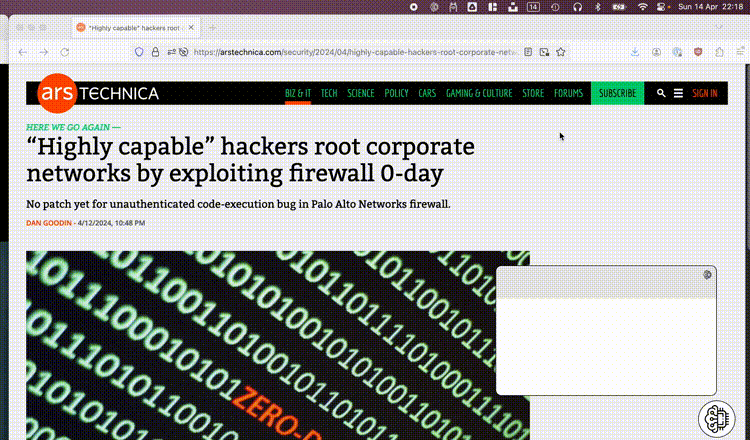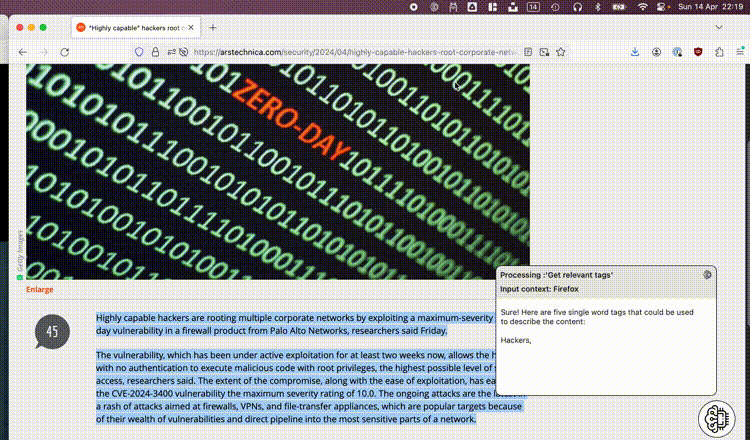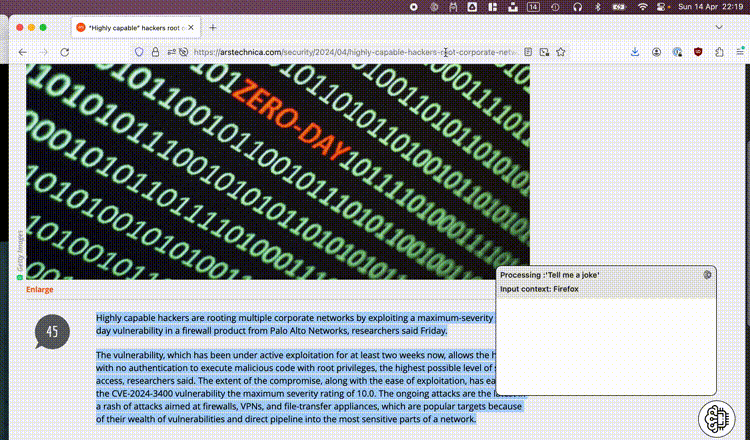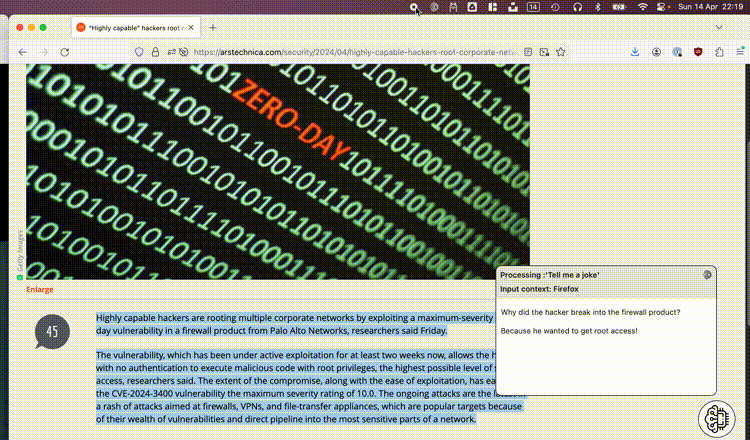
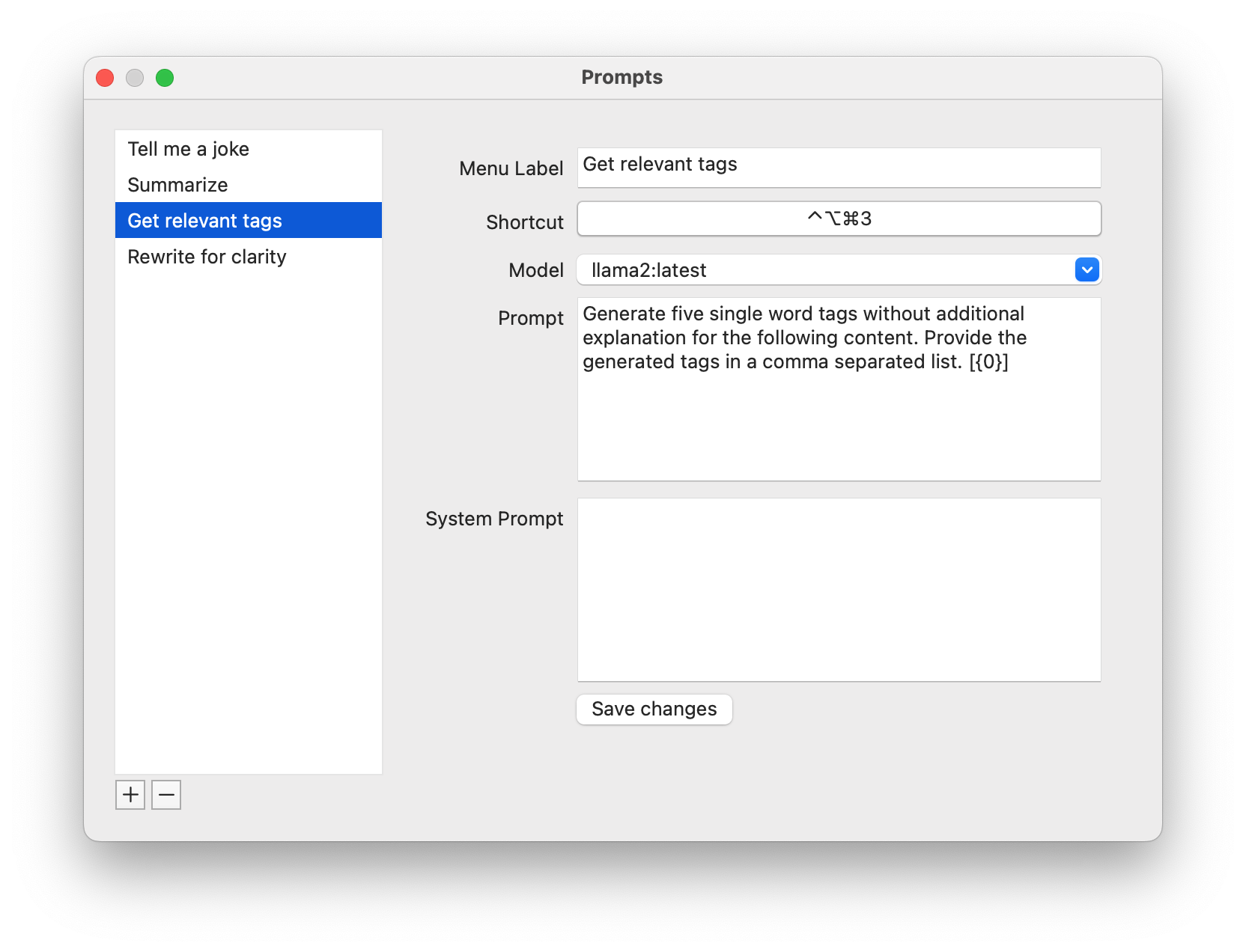
As mentioned above we’re not looking to build a chatbot but we still need to be able to specify what we want and when to execute. For this I fell back to my previous experiences which resulted in yet another toolbar utility. Conceptually it makes sense to define and create your own prompts, this way everybody is empowered to create and set up their own power tools. By hooking up our prompts to global shortcuts, executing an action is as simple as selecting some text and pressing the correct keys on your keyboard.
Based on how fast responses can be generated, it could make sense to make this behave mostly asynchronous and in the background. It could even be very interesting to enable some automation or event chaining. For example automatically executing a next action when the result is completed. I decided however to initially not overdo it and maybe reconsider after using this for a while.
Toolbar Brain
All the context above resulted in a small ‘toolbar brain’ utility. Prompts are initiated by pressing your chosen shortcut keys on your keyboard or through the menu. Whatever text is selected in your active window will be used as input context. By allowing users to manage their own prompt presets, it can easily be tweaked to add value for anyone.