Use case
I have a bad habit of taking many screenshots. As-in a lot of screenshots, sometimes important, sometimes not so much. On macOS these automatically get a timestamp in their name, so my screenshots folder has a nice big list of historic files. At this point it can be a problem to quickly find something back when you need it.
While the best thing to do would probably be to correctly name and move these screenshots, or maybe even link calendar event metadata if available, I decided to validate how far I could get with artificial intelligence. This post describes my results attempting this.
Azure Cognitive Services
My first approach for this problem builds on the Computer Vision capabilities offered by Azure Cognitive Services. Microsoft offers all these capabilities are available through an SDK. My implementation used the C# version but it’s also available for many other languages and runtimes. The SDK is very straightforward to use and allowed me to get some results very quickly.
var visionClient = new ComputerVisionClient(new ApiKeyServiceClientCredentials(_visionSubscriptionKey))
{
Endpoint = _visionEndpoint
};
var features = new List<VisualFeatureTypes?> { VisualFeatureTypes.Description, VisualFeatureTypes.Tags };
var analysis = await visionClient.AnalyzeImageInStreamAsync(imageStream, visualFeatures: features);
Azure Cognitive Services gives us useful info about our images. For our use case, namely analysing screenshots, it is not that interesting however. Underlying it is optimised for ‘normal’ images and gives great results with object, landmark, brand, and celebrity detection. The summaries and tags which you get for screenshots is less useful. The tags I would get are for example ‘font’, ‘screenshot’ and ‘text’. It does do a good job however at giving correct information and by ignoring some specific tags you can prioritise the more useful ones.
I also tried out combining this image analysis with OCR (optical character recognition). Through the same Azure SDK I’m already using, getting the text from our image is only some lines of code away. The data you get back is very good but making sense of this info in an automated way is tricky. It’s hard to build logic to define what text is and isn’t important and which items to consider when summarizing or describing the contents.
Azure Machine Learning
Our first approach gives back some useful information but, as it is somewhat limited for the use case I’m trying to solve, I went back to the drawing board to look at what other options are available. Through the base cognitive services, we’re mainly doing ‘image classification’. As a baseline however broader ‘document classification’ could be more interesting for us, where we focus less on all the image contents, and more on what the document on its own represents.
This type of classification used to be mainly handled by first applying OCR and then running a model on those contents. On the other hand, there are also pure vision models which ignore the text and focus on document layout for classification. Combining these two together in a multimodal transformer you get a model which considers both the text and the visual information at the same time. Hugging Face has a great blog post going in more detail about all the variants and approaches towards Document AI functionalities.
Based on this information I started trying out the Donut model. There is a pre-built model available which is trained on the RVL-CDIP dataset. This is a big document dataset which is trained on 16 classes like ‘form’, ‘email’ and ‘advertisement’. Initial tests on my local machine showed some promise correctly defining images into, for example, invoice and presentation categories.
As we’re now working with a custom AI model, we can’t use the base Azure services anymore to execute this. Donut is available on Hugging Face and there is a beta integration available between Hugging Face and Azure. This integration is currently only available for NLP models however so we can’t use this for our vision model. For custom machine learning tasks Azure has a separate Azure Machine Learning offering which exposes an enterprise-grade service to create, train and execute AI models.
In this case I’m only interested in one aspect of the full offering, deploying my model to the cloud so it is available as an endpoint where I can just send my images to. This is achieved by creating an Azure Machine Learning endpoint. There are some variations depending on the type of machine learning model you’re using but all of them follow the same conventions in usage. You’re also able to deploy and validate everything locally before deploying to the cloud. Once the endpoint is online, it can be further monitored in the Azure Machine Learning Studio.
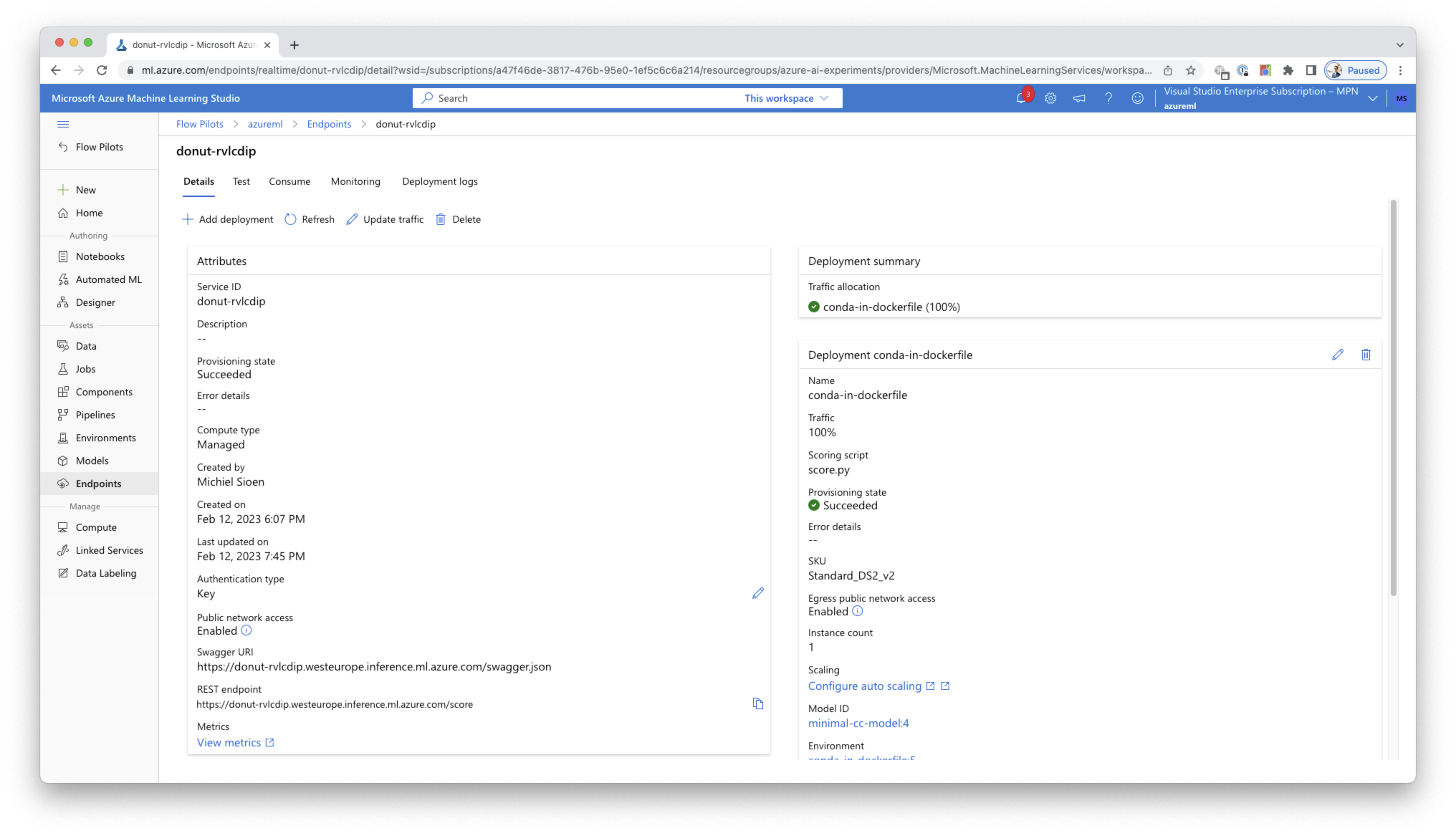
The model we’re currently using allows retraining. For our use case this could be hugely beneficial to, for example, also train the model to recognise Microsoft Teams meetings and other software applications.
Bringing it all together
To bring everything together I decided to create a small macOS utility which lives in the menu bar and watches a set of directories. Any new file which matches the requirements will be picked up and automatically sent through both the Azure Cognitive Services and our Azure ML online endpoint as described above. The info we get back from our AI services is added to the image in the form of tags. A small gif of this utility in action can be seen below.
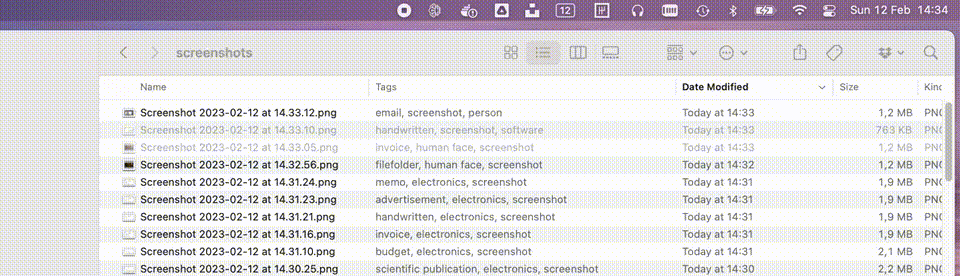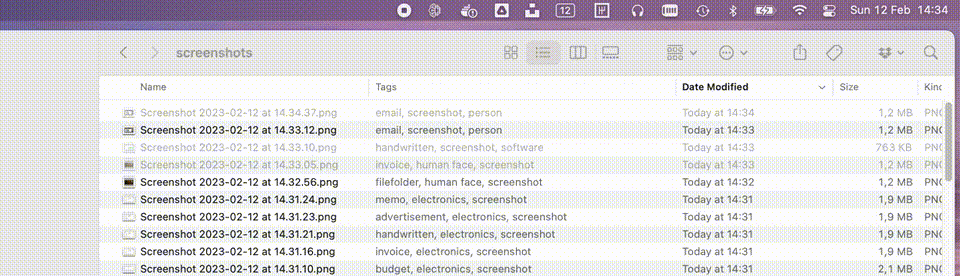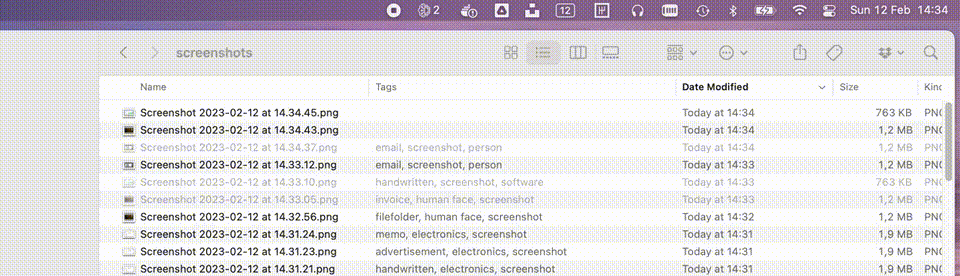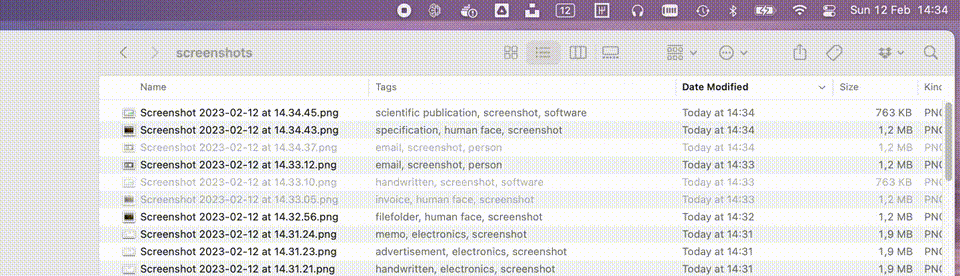
The full source code of this utility can be found on my GitHub. The readme also contains all commands I used to create and deploy the models.