This post is part of a bigger series. Read the series introduction for the full context.
Facts & figures
Squidex positions itself as follows:
“How modern companies manage their content”
“You don’t need another system for your content. You need it on a single place. Centralized, structured and with seamless integrations to other systems. Available from everywhere and for all digital platforms, such as Apps, websites and server applications.”
Main differentiators:
- There’s a strong focus on data and the data editing experience
- The underlying event sourcing architecture allows for some nice features like versioning, audit trails and built-in event triggers
- Easily manage multiple content applications from one place
Tech Stack:
- Open source / MIT licensed
- 1800+ stars on GitHub
- Built with ASP.NET Core for the API layer and Angular for the frontend
- MongoDB is currently the only supported database, support for other databases is defined on the roadmap
- You get GraphQL and REST options out of the box
You can host Squidex either yourself as a self-hosted solution or through the Squidex Cloud SaaS offering.
Headless CMS functionality
Architecting data
In Squidex everything revolves around schemas. A schema defines what your content will look like.
On the highest level you define the base properties your content will have. On every property you have the option to tweak the requirements further by finetuning the validation rules or input rules.
Out of the box all the content types you would expect are available. In case there is a type which you’re missing there are some customization possibilities which I’ll touch on further in this post.
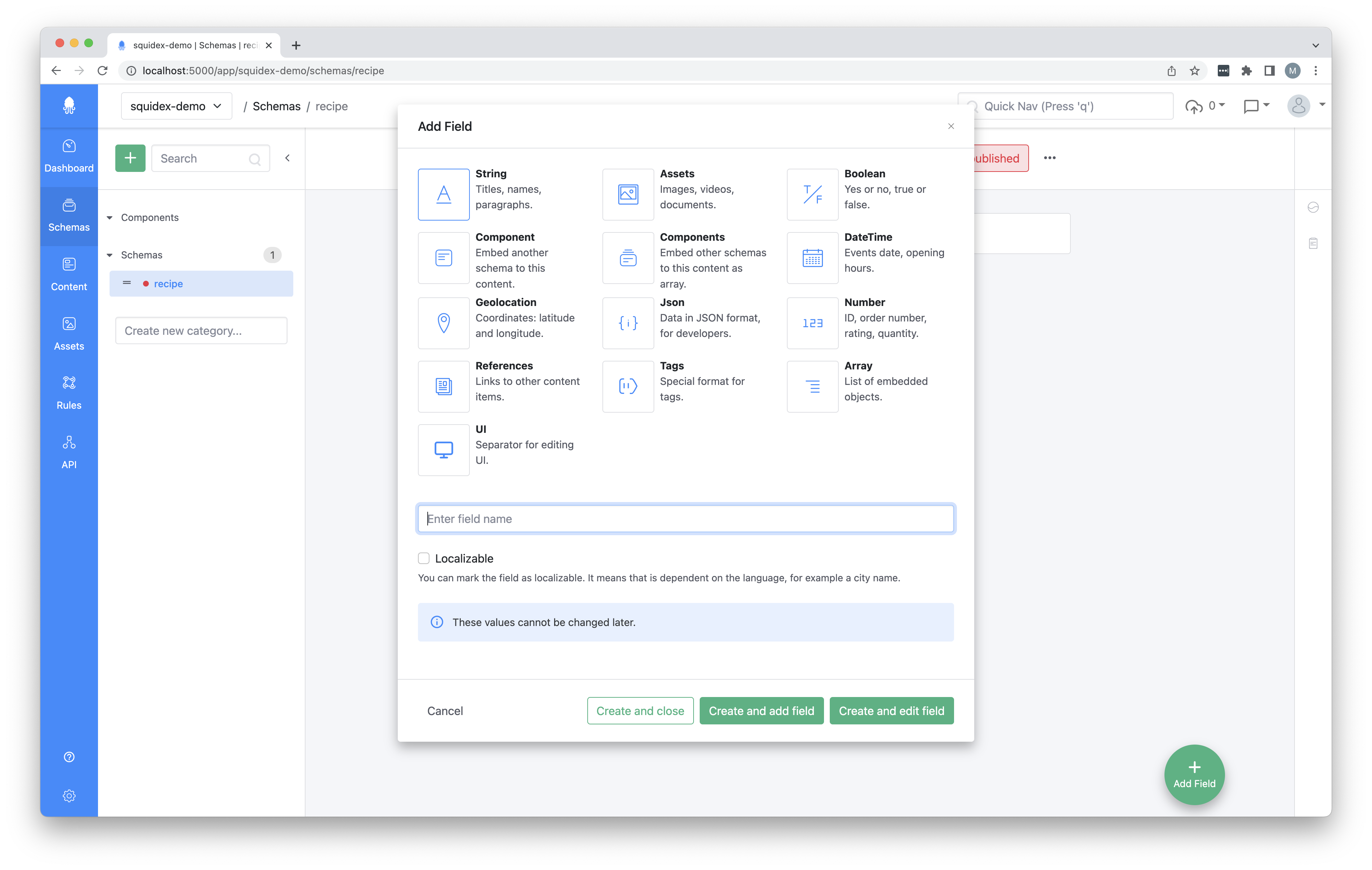
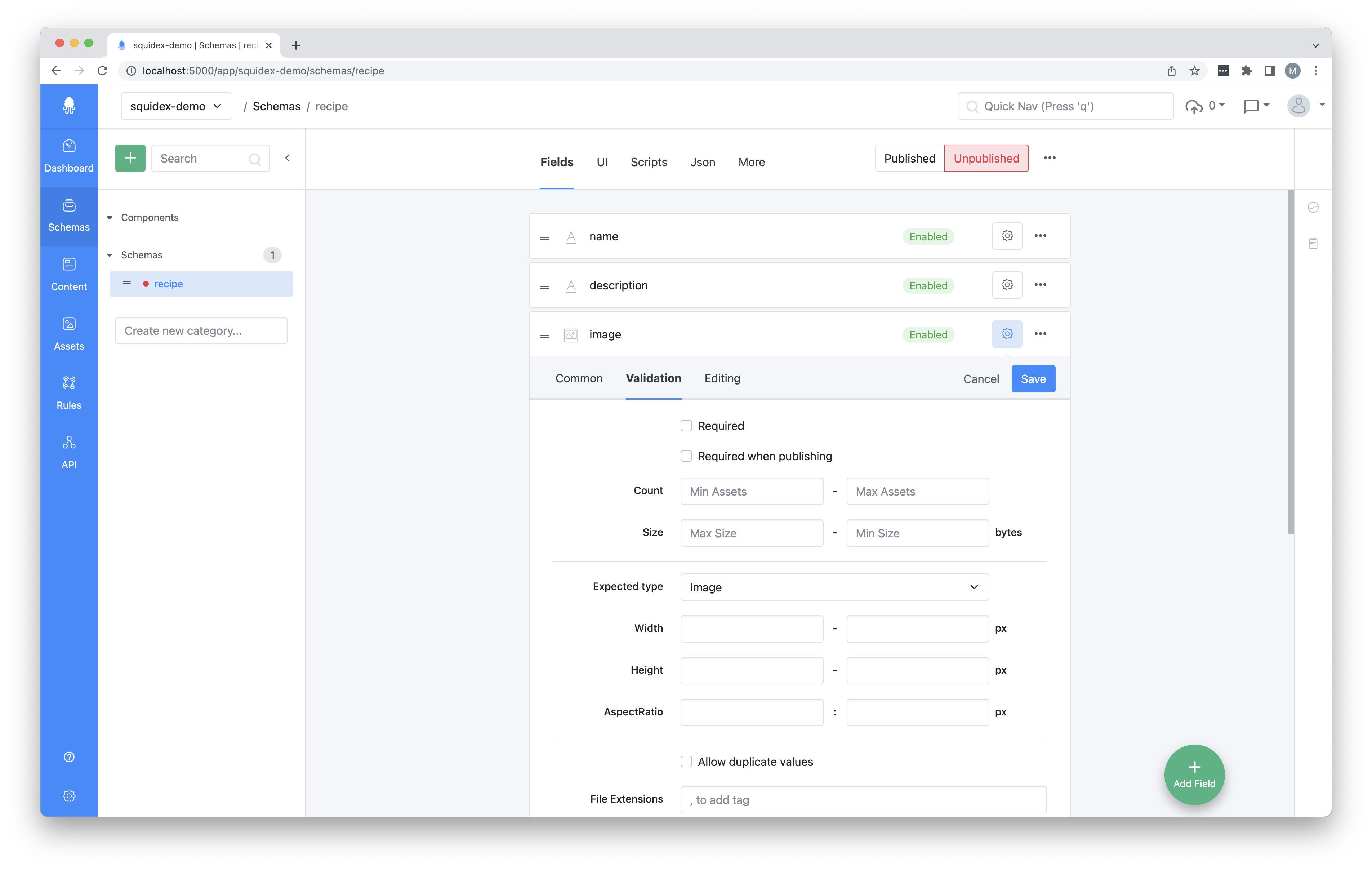
Creating data
Once you have a schema defined you are able to start creating content. The content creation experience follows the schema as defined in your architecture and will clearly show issues as well if applicable. You can choose to immediately publish the content or to keep it in a draft state initially. As soon as it is published, any new changes will also automatically be published on save except if you create a new draft. This flow however can sometimes be a bit confusing to know what is and is not live even though there is a very nice version/compare viewer.
Where a developer or admin typically creates the content structure, in many cases a different role is introduced for content editors which only are able to create content. It is possible to tweak this flow yourself to for example require approval before changes are accepted.
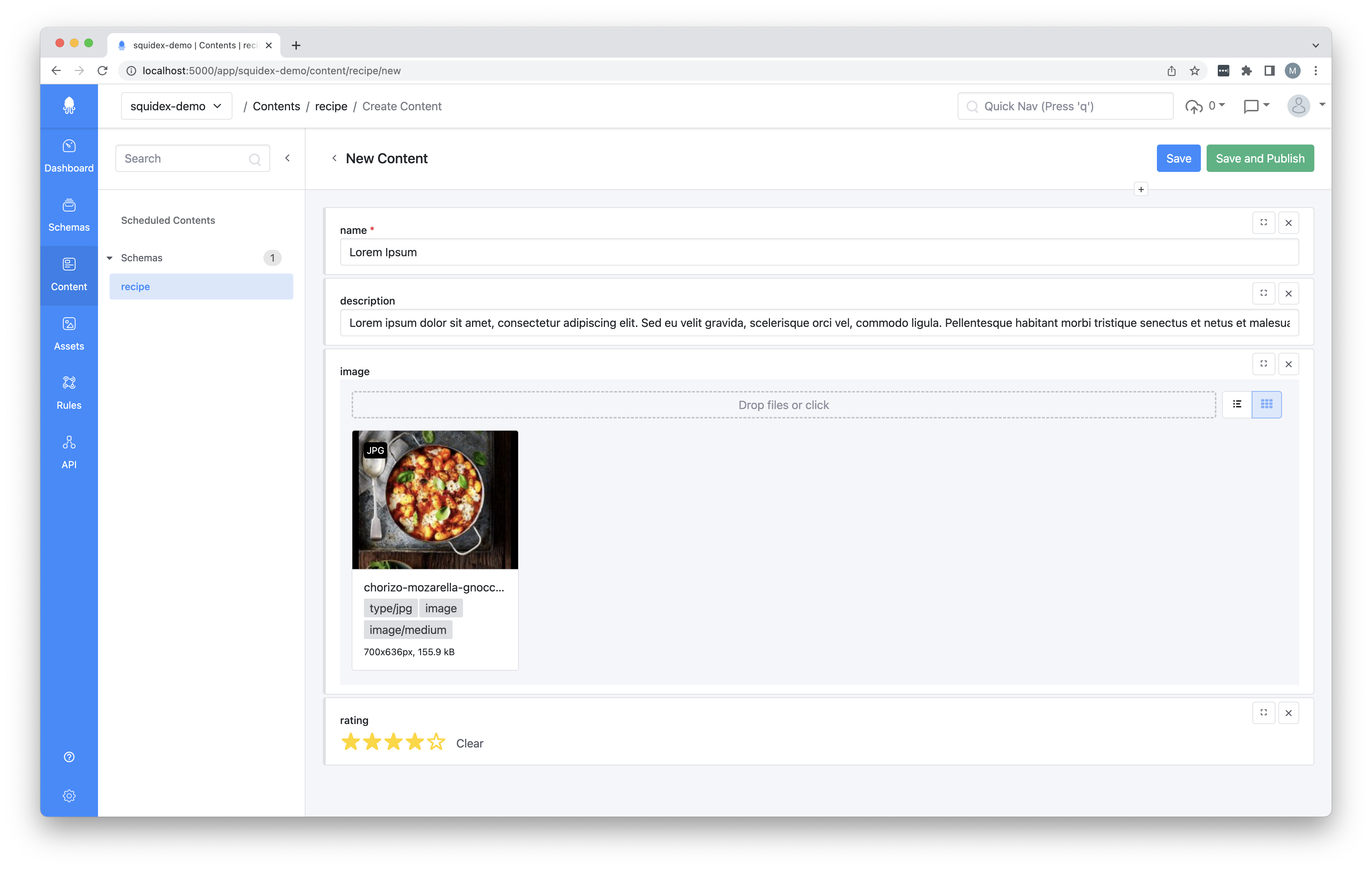
Consuming data
Squidex has some nice features supporting data consumption. If you prefer consuming your data with a REST API you can very easily use the OpenAPI document which is available through the settings. New, updated versions are automatically generated for you containing all data fields from the schemas you created. You can also add a great many options and filters in your queries out of the box.
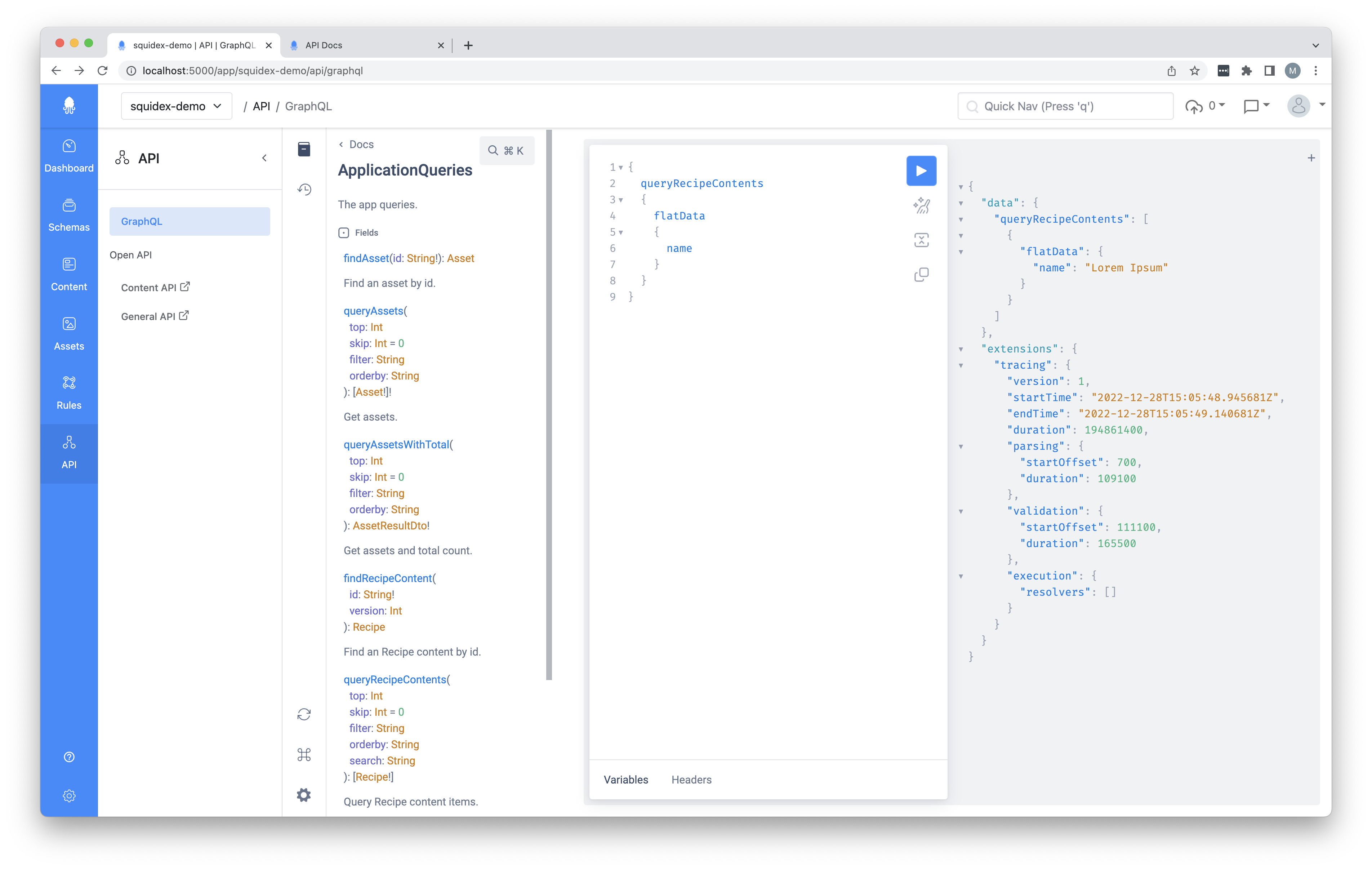
A GraphQL interface is available which has autocompletion support and a small documentation browser to see the available queries and classes.
There’s one important thing to consider on validating the data consumption. If you use the built-in GraphQL editor, it will use the permissions of the user you are currently logged in with. This means that the data you get back may not be an exact match compared to using the REST API or calling the GraphGQL API from an external tool. Draft content will for example be visible here which you may not expect.
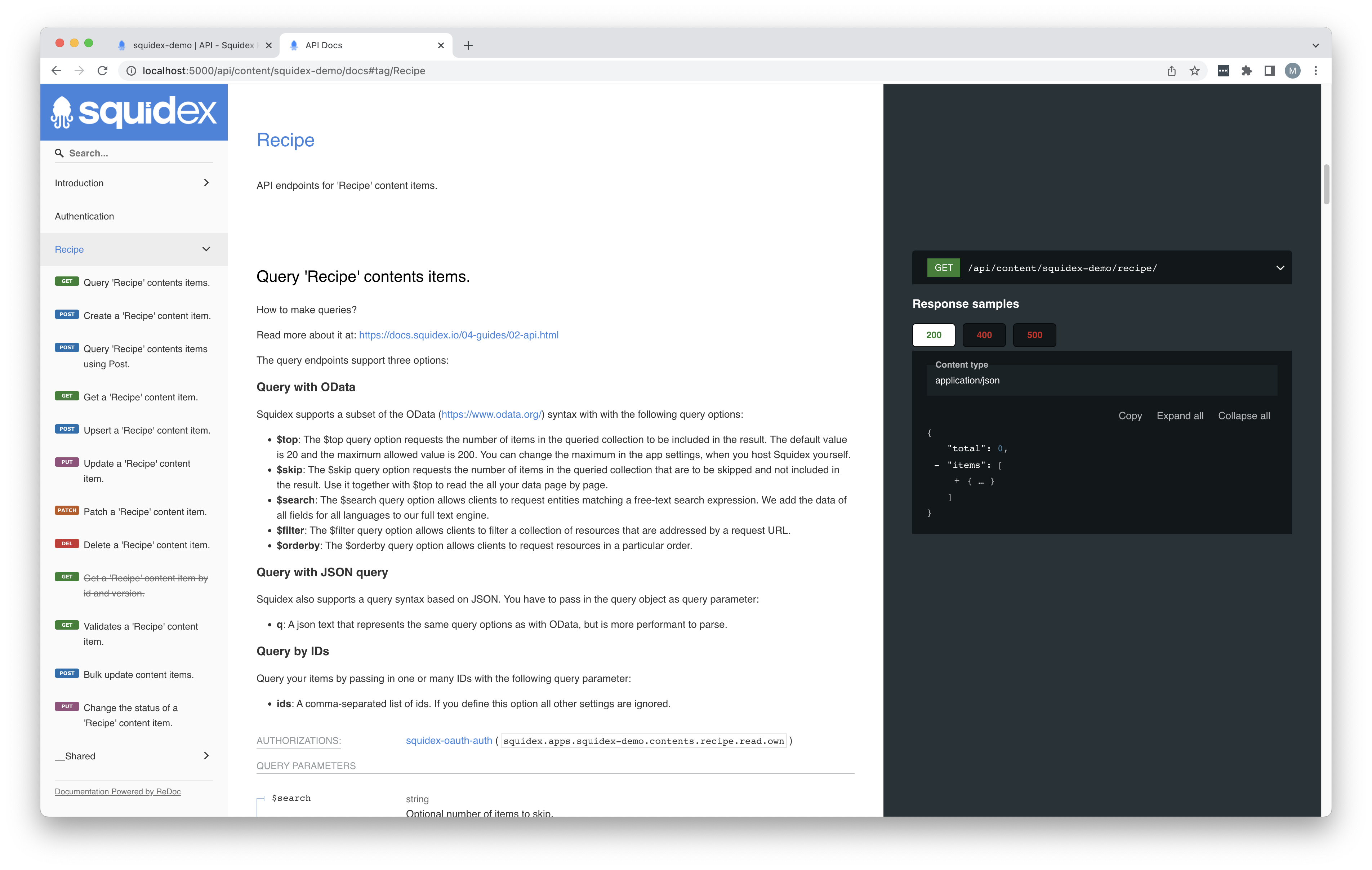
User management / Authentication & authorization
For a headless CMS there are two types of authentication to look at: how do you manage your CMS users and how do you manage your data consumers.
Your main users are managed within the CMS itself. Some base permissions of a user can be managed across the platform, but the actual role of a user has to be defined per application. On an application level you’re also able to define your own custom roles if you need this. There is no full user interface to manage deep down permissions, but the system allows you to set these in a very granular way. It is possible to link Microsoft / GitHub and Google third party logins as well. It is unclear to me if these could be linked automatically to a role.
For data consumption you create one or more clients in the app settings. A client is linked to a role, this means that managing API permissions works the same way as managing your user roles.
The developer story
Getting started
The developer documentation is quite extensive on all the possible methods you could use to deploy Squidex. All the main cloud providers have a separate section, aside from the information you would use for local development. All the necessary dependencies are also easily made available, for example a ready to start docker image for a local database.
I did have some issues getting Squidex running locally, mainly due to SSL certificates not being happy. The documentation does mention this as well if you’re running under localhost. In the end I forced everything to run on without https which worked fine. It probably would have been better to setup a custom host with a self-signed certificate.
Customization
The Management UI itself cannot be extended without fully building from source, there is however a very nice feature which does allow customizing your editor experience. You are able to define a mini ‘micro-frontend’ for a component which can be linked as an editor url on any item. This allows you to easily add new types if required or to finetune how you want your content editors to work with data.
In backend code you’re able to create your own plugins. This allows you for example to inject your own API controllers, hook into the commands or execute actions on incoming events for use cases which aren’t possible through the existing rules engine.
If these options aren’t enough you could always modify the source code itself as a last resort. This makes updating to a newer version harder to manage however.
Pros and cons of Squidex
Every system out there has benefits and downsides depending on your use case. Here are some items to take into consideration.
- The focus of Squidex is clearly on data and data management from a headless perspective and this shows. The interface and way of working for the core elements is very intuitive for working with data. This applies both to ‘simple’ objects but for example also for more advanced object relations.
- There is excellent to-the-point documentation for the information you actually need.
- The API features like the automatic OpenAPI document generation and GraphQL are very nice.
- The micro-frontend approach to customize the editing experience works quite well and also ensures your customization doesn’t block updating the core system.
- Squidex makes nice use of its underlying architecture choice to enable features like the rule engine, content history and data comparisons.
- Some more advanced features are very powerful but can be confusing to use. For example, some of the versioning or draft functionalities can be hard to figure out.
- If using MongoDB is a blocker for you, this CMS is (currently) not for you.
Resources
https://squidex.io/
Official webpage of Squidex.
https://docs.squidex.io/
Developer / user documentation for Squidex
https://support.squidex.io/
Support forum for any issues and/or questions about Squidex
https://github.com/Squidex/squidex
Source code
Posts in this series: